

Φωτογραφία: τα μέλη της ερευνητικής ομάδας του Τμ. Πληροφορικής που ανέπτυξαν τον φωτονικό επεξεργαστή Τεχνητής Νοημοσύνης. Διακρίνονται από αριστερά: όρθιοι οι επίκουρος καθηγητής Νικόλαος Πασσαλής, καθηγητής Νικόλαος Πλέρος, Καθηγητής Αναστάσιος Τέφας, καθιστοί οι Χρήστος Παππάς, Δρ. Μιλτιάδης Μόραλης-Πέγιος, Δρ. Απόστολος Τσακυρίδης, Δρ. Γεώργιος Γιαμουγιάννης και Δρ. Μάνος Κίρτας.
ΣΗΜΕΙΩΣΗ ΑΝΙΧΝΕΥΣΕΩΝ: Στις Ανιχνεύσεις δημοσιεύθηκε σήμερα η είδηση κατασκευής φωτονικού επεξεργαστή Τεχνητής Νοημοσύνης με τη μεγαλύτερη παγκοσμίως Υπολογιστική Ισχύ απο το Τμήμα Πληροφορικής του ΑΠΘ. Μπορείτε να την διαβάσετε ΕΔΩ.
Παρακάτω παραθέτουμε ολόκληρη την σχετική εργασία μεταφρασμένη στα ελληνικά. Στον σύνδεσμο στο τέλος του κειμένου μπορείτε να βρείτε την εργασία στα αγγλικά.
Editor’s Pick – Open Access
Special Collection: Optical Computing Systems
Christos Pappas (Συγγραφέας Επικοινωνίας)
Antonios Prapas
Theodoros Moschos
Manos Kirtas
Odysseas Asimopoulos
Apostolos Tsakyridis
Miltiadis Moralis-Pegios
Chris Vagionas
Nikolaos Passalis
Cagri Ozdilek
Timofey Shpakovsky
Alain Yuji Takabayashi
John D. Jost
Maxim Karpov
Anastasios Tefas
Nikos Pleros
APL Photonics 10, 110805 (2025)
https://doi.org/10.1063/5.0271374
Ο συνεχώς αυξανόμενος όγκος δεδομένων που προκύπτει από την εκθετική κλίμακα των μοντέλων Τεχνητής Νοημοσύνης (AI) και Βαθιάς Μάθησης (DL) αποτέλεσε κίνητρο για έρευνα σε εξειδικευμένους επιταχυντές AI, προκειμένου να συμπληρωθούν οι ψηφιακοί επεξεργαστές. Τα Φωτονικά Νευρωνικά Δίκτυα (PNNs), με την ιδιαίτερη ικανότητά τους να αξιοποιούν την αλληλεπίδραση πολλών φυσικών διαστάσεων —συμπεριλαμβανομένων του χρόνου, του μήκους κύματος και του χώρου— έχουν προταθεί με αξιόπιστη υπόσχεση για ενίσχυση της υπολογιστικής ισχύος και της ενεργειακής απόδοσης στους επεξεργαστές AI.
Στο παρόν άρθρο, αποδεικνύουμε πειραματικά έναν νέο φωτονικό επιταχυντή AI, βασισμένο σε πολυδιάστατο δρομολογητή υπό διάταξη κυματοδηγών (AWGR), ο οποίος μπορεί να εκφορτίζει (offload) λειτουργίες γραμμικής άλγεβρας που περιορίζονται από το εύρος ζώνης, ενώ αφήνει την ιεραρχία μνήμης, τον έλεγχο και τις μη γραμμικότητες στα ηλεκτρονικά. Ο επιταχυντής μπορεί να εκτελεί πολλαπλασιασμούς τανυστών με συνολική υπολογιστική ισχύ-ρεκόρ 262 TOPS, προσφέροντας περίπου 24× βελτίωση σε σχέση με υπάρχοντες οπτικούς επιταχυντές βασισμένους σε κυματοδηγούς.
Αποτελείται από έναν AWGR 16 × 16, ο οποίος αξιοποιεί τη διαίρεση χρόνου, μήκους κύματος και χώρου (T-W-SDM) για την κωδικοποίηση βαρών και εισόδων, σε συνδυασμό με ενσωματωμένη χτένα συχνοτήτων (frequency comb) από Si₃N₄ για πολυκαναλική παραγωγή μηκών κύματος.
Ο φωτονικός επιταχυντής AI επικυρώθηκε πειραματικά τόσο σε πλήρως συνδεδεμένα (FC) όσο και σε συνελικτικά νευρωνικά δίκτυα (CNN). Το FC και το CNN εκπαιδεύτηκαν για εντοπισμό επιθέσεων DDoS και ταξινόμηση MNIST, αντίστοιχα. Η πειραματική διεξαγωγή inference στα 32 Gbaud πέτυχε δείκτη Cohen’s κ = 0.8652 για την ανίχνευση DDoS και ακρίβεια 92.14% για την ταξινόμηση MNIST, επιδόσεις που προσεγγίζουν πλήρως τα αντίστοιχα αποτελέσματα λογισμικού.

Θέματα
Τεχνητή νοημοσύνη, Τεχνητά νευρωνικά δίκτυα, Επεξεργασία φυσικής γλώσσας, Τηλεπικοινωνιακή μηχανική, Χτένες συχνοτήτων, Πολυπλεξία διαίρεσης μήκους κύματος, Λέιζερ, Δρομολογητής κυματοδηγών υπό διάταξη
I. ΕΙΣΑΓΩΓΗ
Οι ηλεκτρονικοί επιταχυντές τεχνητής νοημοσύνης συνεχίζουν να βελτιώνονται σε επίπεδο συστήματος· ωστόσο, η επιβράδυνση της κλασικής κλιμάκωσης τάσης/συχνότητας («power wall», «dark silicon»)¹, σε συνδυασμό με τη ραγδαία αύξηση της υπολογιστικής ζήτησης για προηγμένη εκπαίδευση AI²,³, οδήγησε σε μια μετατόπιση παραδείγματος προς εξειδικευμένο υλικό το οποίο μπορεί να συμπληρώνει τις ψηφιακές πλατφόρμες, διατηρώντας την ανάπτυξη υπολογιστικής ισχύος και ενεργειακής απόδοσης.
Στο πλαίσιο αυτό, τα φωτονικά νευρωνικά δίκτυα (PNNs) έχουν προβλεφθεί θεωρητικά ότι διαθέτουν τα χαρακτηριστικά για να αντιμετωπίσουν αυτές τις υπολογιστικές και ενεργειακές προκλήσεις, επιτρέποντας υπολογιστική ισχύ κλίμακας peta και ενεργειακή απόδοση επιπέδου fJ/λειτουργία⁴–⁶, αξιοποιώντας το υψηλό εύρος ζώνης και τις χαμηλές απαιτήσεις ισχύος, σε συνδυασμό με τη διαρκώς αυξανόμενη ωριμότητα της φωτονικής ολοκλήρωσης.
Ωστόσο, η μετάβαση από τις θεωρητικές προβλέψεις στις πειραματικές επιδείξεις⁶–³¹ αποκάλυψε μία διαφορετική πραγματικότητα για τα PNNs, η οποία χαρακτηρίζεται κυρίως από αρχιτεκτονικές προκλήσεις που εμποδίζουν τη διασφάλιση επεκτάσιμων διατάξεων. Δεδομένου ότι τα ολοκληρωμένα φωτονικά στοιχεία υστερούν χωρικά σε αποτύπωμα σε σχέση με τα ηλεκτρονικά τους αντίστοιχα, τα PNNs μπορούν να αντιμετωπίσουν το ζήτημα της επεκτασιμότητας μόνο μέσω αρχιτεκτονικών σχημάτων που υποστηρίζουν αρμονικά την αλληλεπίδραση μεταξύ των χρονικών και χωρικών διαστάσεων, σε συνδυασμό με τα παραδοσιακά πλεονεκτήματα της οπτικής —δηλαδή τη διάσταση μήκους κύματος και τη λειτουργία υψηλής ταχύτητας— τα οποία όμως εξακολουθούν να απουσιάζουν από τις σύγχρονες ολοκληρωμένες φωτονικές αρχιτεκτονικές Matrix-Vector-Multiply (MVM).
Πιο συγκεκριμένα, οι πειραματικές επιδείξεις στις Αναφ. 7 και 16 αξιοποιούν φωτονικά πλέγματα (photonic meshes) και πολυπλεξία διαίρεσης χώρου (SDM), εκτελώντας υπολογισμούς μέσω διαδοχικών κόμβων παρεμβολέων Mach–Zehnder (MZI). Η προσέγγιση αυτή συσχετίζει άμεσα τον φυσικό με τον υπολογιστικό χώρο, γεγονός που συνεπάγεται ένα όριο επεκτασιμότητας, καθώς τα μεγαλύτερα δίκτυα θα οδηγούσαν αναπόφευκτα σε υψηλότερες απώλειες εισαγωγής.³²
Από την άλλη πλευρά, έχει πραγματοποιηθεί εκτεταμένη έρευνα σε αρχιτεκτονικές PNN που αξιοποιούν την τεχνική πολυπλεξίας διαίρεσης μήκους κύματος (WDM).¹⁵,²⁶ Το κύριο δομικό στοιχείο αυτών των αρχιτεκτονικών είναι η διάταξη μικροδακτυλιοειδών συντονιστών (MRR bank), η οποία αποτελείται από πολλαπλούς MRRs τοποθετημένους μεταξύ δύο παράλληλων κυματοδηγών και είναι υπεύθυνη για την υλοποίηση επιλεκτικής στάθμισης ανά κανάλι. Παρά την εντυπωσιακή τους απόδοση σε ένα εύρος εφαρμογών, η υπολογιστική ισχύς και το μέγεθος του κυκλώματος σε αυτές τις διατάξεις μπορούν να αυξηθούν μόνο μέσω της αύξησης του αριθμού των πηγών λέιζερ. Ταυτόχρονα, απαιτούν τη σύγχρονη λειτουργία και τον ακριβή έλεγχο μεγάλης ποσότητας συντονιζόμενων στοιχείων, εγείροντας πρόσθετες ανησυχίες σχετικά με την κατανάλωση ισχύος και τις προοπτικές επεκτασιμότητας.
Το μέγεθος ενός φωτονικού κυκλώματος MVM μπορεί να επιτύχει απεριόριστη επεκτασιμότητα μόνο μέσω της αξιοποίησης της πολυπλεξίας διαίρεσης χρόνου (TDM). Οι συγγραφείς στις Αναφ. 12, 14, 20 και 27 απέδειξαν την αποτελεσματική συνεργεία SDM και TDM ενσωματώνοντας κόμβους εισόδου/βάρους υψηλής ταχύτητας και δέκτες ολοκλήρωσης χρόνου (time-integrating receivers) για τη λειτουργία συσσώρευσης. Ως αποτέλεσμα, το μέγεθος του PNN αυξάνεται αποτελεσματικά χωρίς την ανάγκη κατασκευής μεγάλων φωτονικών κυκλωμάτων, ενώ η χρήση δέκτη ολοκλήρωσης χρόνου επιτρέπει την αξιοποίηση μετατροπέων αναλογικού-σε-ψηφιακό (ADCs) χαμηλής ισχύος και χαμηλού κόστους, καθώς μειώνει τις απαιτήσεις εύρους ζώνης τους.
Ωστόσο, οι αρχιτεκτονικές αυτές παραλείπουν τη χρήση πολυπλεξίας διαίρεσης μήκους κύματος (WDM), η οποία αποτελεί τον τυπικό παράγοντα παραλληλοποίησης στην οπτική τεχνολογία. Η απουσία της περιορίζει την ικανότητα των PNNs να αξιοποιήσουν πλήρως όλους τους διαθέσιμους βαθμούς ελευθερίας, στερώντας τους έτσι τη δυνατότητα να ενισχύσουν ακόμη περισσότερο τη υπολογιστική ισχύ και την ενεργειακή απόδοση.
Τα οφέλη της πρόσθετης ενσωμάτωσης της διάστασης μήκους κύματος σε διατάξεις πολυπλεξίας χρόνου–χώρου έχουν αναδειχθεί σε πιο πρόσφατες επιδείξεις,²³,²⁸,²⁹ οδηγώντας σε υπολογιστικές ισχείς έως και 11 TOPS,²³ που αποτελούν μέχρι σήμερα το ρεκόρ για όλους τους σύγχρονους οπτικούς επεξεργαστές βασισμένους σε κυματοδηγούς.
Μέχρι όπου γνωρίζουμε, μόνο τα διαθλαστικά οπτικά συστήματα έχουν καταφέρει να υπερβούν το όριο των 100 TOPS σε υπολογιστική ισχύ,³³–³⁵ είτε μέσω chiplets βασισμένων σε διαθλαστικές αρχές³³ είτε μέσω υβριδικού συνδυασμού διαθλαστικών περιοχών με modules inference.³⁴,³⁵ Ωστόσο, η χρήση διαθλαστικών στοιχείων απαιτεί την εκ των προτέρων κωδικοποίηση των τιμών βαρών κατά τη διαδικασία κατασκευής, και ως εκ τούτου περιορίζει εγγενώς τους φωτονικούς επιταχυντές AI σε μία συγκεκριμένη εργασία inference. Έτσι, οι υψηλές υπολογιστικές ισχείς που προσφέρουν οι διαθλαστικοί επεξεργαστές οπτικών κυματοδηγών επιτυγχάνονται εις βάρος της ευελιξίας και της καθολικότητάς τους, περιορίζοντας την αξιοποίησή τους μόνο σε εφαρμογές ειδικού σκοπού και εγκαταλείποντας τον γενικό χαρακτήρα χρήσης.
Σε αυτό το άρθρο…
Σε αυτό το άρθρο παρουσιάζουμε πειραματικά τον πρώτο φωτονικό επιταχυντή τεχνητής νοημοσύνης που τροφοδοτείται από πηγή λέιζερ microcomb και είναι ικανός να εκτελεί πράξεις Matrix-by-Tensor-Multiply (MbTM) με υπολογιστική ισχύ-ρεκόρ 262 TOPS. Η προτεινόμενη αρχιτεκτονική αποτελείται από ένα AWGR 16 × 16, ευρυζωνικούς διαμορφωτές έντασης για κωδικοποίηση βαρών και εισόδων στα 32 Gbaud, και μια πηγή λέιζερ με χτένα συχνοτήτων (frequency comb) από Si₃N₄ για δημιουργία πολλαπλών μηκών κύματος.
Αυτή η προσέγγιση επεκτείνει την πρόσφατη εργασία μας πάνω στα πρώτα AWGR-based PNNs,³⁶ επιδεικνύοντας αύξηση άνω του 60% στην συνολική υπολογιστική ισχύ και μια ~8.5% υψηλότερη ταξινομική ακρίβεια, αξιοποιώντας ρυθμούς ρολογιού στα 32 Gbaud και κανάλια μήκους κύματος παραγόμενα από microcomb-laser.
Η τοπολογία στηρίζεται στις κυκλικές ιδιότητες δρομολόγησης μήκους κύματος του AWGR και υποστηρίζει ταυτόχρονα πολυπλεξία διαίρεσης χρόνου, μήκους κύματος και χώρου (TWSDM) για την κωδικοποίηση βαρών και διανυσμάτων εισόδου, σχηματίζοντας ένα ισχυρό πλαίσιο για πράξεις μήτρας και τανυστών.
Για την επικύρωση της επίδοσης του προτεινόμενου επιταχυντή τανυστών τόσο σε FC όσο και σε CNN διατάξεις, εκπαιδεύσαμε δύο μοντέλα Βαθιάς Μάθησης για διαφορετικές εφαρμογές, λαμβάνοντας υπόψη το optics-informed πλαίσιο εκπαίδευσης DL⁴ ώστε να προσαρμόζεται στους περιορισμούς του φωτονικού υλικού—όπως θόρυβος¹³,³⁷, κβαντοποίηση³⁸,³⁹ και μη-αρνητικότητα τιμών⁴⁰.
Η πρώτη εφαρμογή ήταν η αναγνώριση επιθέσεων DDoS με χρήση ενός πλήρως συνδεδεμένου NN (FCNN), όπου ο επιταχυντής πέτυχε πειραματική βαθμολογία Cohen’s κ = 0.8652 για 2048 δείγματα inference—απόδοση πολύ κοντά στη λειτουργία λογισμικού.
Η δεύτερη εφαρμογή ήταν η ταξινόμηση χειρόγραφων ψηφίων (MNIST) μέσω ενός συνελικτικού NN (CNN), όπου το inference στο υλικό έδειξε ακρίβεια 92.14%, παρουσιάζοντας μόλις 1.55% υποβάθμιση σε σχέση με την ακρίβεια λογισμικού.
II. CONCEPT OF MATRIX-BY-TENSOR MULTIPLICATOR ΚΑΙ ΑΡΧΗ ΛΕΙΤΟΥΡΓΙΑΣ
Η προτεινόμενη μηχανή πολλαπλασιασμού matrix-by-tensor, στη γενική της διάταξη N × K × S, απεικονίζεται στο εννοιολογικό διάγραμμα της Εικ. 1(a). Αποτελείται από ένα AWGR N × N, με N και K ευρυζωνικούς διαμορφωτές συνδεδεμένους στις εισόδους #N και στις εξόδους #K του (με Κ ≤ N), αντίστοιχα.
Ένα πολυ-λ (multi-λ) ρεύμα, παραγόμενο από πολυπλεξία N ακτίνων λέιζερ, χωρίζεται σε N κανάλια ίσης ισχύος, με το i-οστό κανάλι (i ∈ [1, N]) να εισέρχεται στον i-οστό ευρυζωνικό διαμορφωτή. Ο διαμορφωτής οδηγείται ηλεκτρικά από το διανυσμα γραμμής βαρών
ᵢ = [wᵢ1, wᵢ2, …, wᵢL],
το οποίο περιέχει L στοιχεία και αποτυπώνεται οπτικά σε όλα τα #N μήκη κύματος, έτσι ώστε η έξοδος κάθε διαμορφωτή i να αποτελείται από σειρά χρόνου μήκους L συμβόλων. Αυτό συνεπάγεται ότι οι υποστηριζόμενες μήτρες βαρών W μπορούν να έχουν N γραμμές και L στήλες, με κάθε διανυσμα γραμμής βαρών Wᵢ να περιέχει L διακριτά σύμβολα που αντιστοιχούν στις διακριτές χρονικές οπές της αναπαράστασής του.
Το AWGR συλλέγει τις εξόδους όλων των διαμορφωτών στις θύρες εισόδου του και επιτρέπει σε όλα τα διανύσματα βαρών W₁, …, W_N να εμφανιστούν σε κάθε θύρα εξόδου j του AWGR (j ∈ [1, K]), αξιοποιώντας τις κυκλικές ιδιότητες δρομολόγησης μήκους κύματος. Ως αποτέλεσμα, ολόκληρη η μήτρα βαρών N × L εμφανίζεται σε κάθε έξοδο j, με κάθε γραμμή βαρών να μεταφέρεται από διαφορετικό μήκος κύματος της πολυ-λ ροής.
Ένας διαχωριστής (splitter) με λόγο 1:S στην έξοδο j αναμεταδίδει (broadcast) τη μήτρα βαρών σε S χωρικά διαχωρισμένα αντίγραφα ίσης ισχύος. Τα παραγόμενα σήματα διέρχονται μέσω ενός ευρυζωνικού διαμορφωτή τοποθετημένου σε κάθε έξοδο του διαχωριστή, με l ∈ [1, S]. Τα ηλεκτρικά διανύσματα εισόδου ˡ οδηγούν τους διαμορφωτές ώστε οι χρονικές στιγμές να αντιστοιχούν στο μήκος L συμβόλων των διανυσμάτων βαρών.
Έτσι, το πολυ-λ σήμα στην έξοδο του διαμορφωτή l μεταφέρει το Hadamard product (HP):
ᵢˡ = ˡ ⊙ ᵢ
μεταξύ του διανύσματος εισόδου ˡ και όλων των διανυσμάτων βαρών ᵢ.
Με τον αποπολυπλέκτη (demultiplexer) του πολυ-λ σήματος στην έξοδο του διαμορφωτή l λαμβάνουμε κάθε L-symbol HP μεταξύ ενός διανύσματος βαρών και του διανύσματος εισόδου. Η συσσώρευση πραγματοποιείται μέσω οπτικού ή οπτοηλεκτρονικού integrator που ολοκληρώνει σε διάρκεια L συμβόλων ώστε να προκύψει το dot-product
dᵢˡ = ˡ · ᵢ,
όπως προτάθηκε στην Αναφ. 41.
Με αυτόν τον τρόπο υπολογίζεται διαφορετικό MbMM (Matrix-by-Matrix Multiply) μεταξύ της μήτρας W και της αντίστοιχης εισόδου L × S που σχηματίζεται από τα S διανύσματα εισόδου ˡ για κάθε θύρα εξόδου j του AWGR, όπως φαίνεται στην Εικ. 1(b).
Αξιοποιώντας τη χωρική διάσταση και εξοπλίζοντας όλες τις K εξόδους AWGR με ένα στάδιο 1:S split-and-modulation MbMM, η προτεινόμενη αρχιτεκτονική εκτελεί K διαφορετικές πράξεις MbMM, μετατρέποντας την αρχιτεκτονική σε διάταξη MbTM, όπου μια μήτρα βαρών N × L πολλαπλασιάζεται με έναν τανυστή εισόδου L × S × K.
Σε μία συνηθισμένη περίπτωση όπου K = N, η διάταξη υποστηρίζει συνολικά N²·S υπολογισμούς. Υποθέτοντας baud-rate B Gbaud για κάθε διαμορφωτή και λόγο S ίσο με τον αριθμό των θυρών N, ο αριθμός υπολογισμών κλιμακώνεται ως O(N³), ενώ η πολυπλοκότητα του κυκλώματος κλιμακώνεται ως O(N²), δίνοντας συνολική υπολογιστική ισχύ
N³·B GMAC/sec,
ή ισοδύναμα
2·N³·B GOPS.
Η Εικ. 1(c) απεικονίζει σχηματικά την αρχιτεκτονική, αναδεικνύοντας όλα τα βασικά δομικά της στοιχεία.
Τέλος, ο ρυθμός φόρτωσης παραμέτρων ορίζεται ως:
Cw × q × B,
όπου Cw είναι ο αριθμός ταυτόχρονων καναλιών βαρών (ενεργοί διαμορφωτές βαρών), q τα bits ανά σύμβολο και B ο baud-rate. Αριθμητικά παραδείγματα περιλαμβάνονται στο Συμπληρωματικό Υλικό, Τμήμα S4.
FIG. 1.

III. ΠΕΙΡΑΜΑΤΙΚΗ ΥΛΟΠΟΙΗΣΗ ΤΟΥ ΕΠΙΤΑΧΥΝΤΗ ΒΑΣΙΣΜΕΝΟΥ ΣΕ AWGR
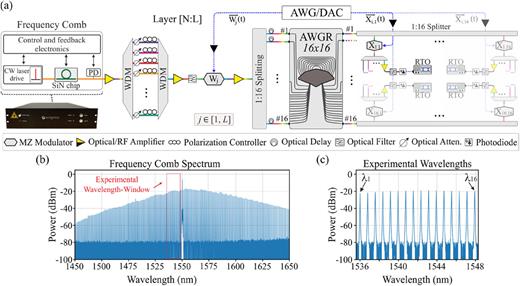
Η πειραματική υλοποίηση της φωτονικής μηχανής MbTM βασισμένης σε AWGR απεικονίζεται στην Εικ. 2(a). Ως πηγή συνεχούς κύματος (CW) χρησιμοποιήθηκε μια χτένα συχνοτήτων (frequency comb) βασισμένη σε νιτρίδιο του πυριτίου (Si₃N₄) — το SLC της Enlightra. Το μπλοκ διάγραμμα αποκαλύπτει τα βασικά δομικά στοιχεία: (i) ένα CW pump laser, (ii) έναν υψηλής ποιότητας μικρο-συντονιστή Si₃N₄ και (iii) μια μονάδα ελέγχου για τα ηλεκτρονικά.
Το φως που συζευγνύεται στην κοιλότητα του δακτυλίου συσσωρεύει ένταση σε κάθε διέλευση· όταν η οπτική ισχύς στον συντονιστή υπερβεί το μη-γραμμικό κατώφλι του υλικού, παράγεται ένα ευρύ φάσμα συχνοτήτων — μια χτένα συχνοτήτων — με ελεύθερο φασματικό εύρος (FSR) 100 GHz. Ο συνδυασμός της υψηλής Kerr μη-γραμμικότητας στο νιτρίδιο του πυριτίου, της διασποράς ομαδικής ταχύτητας και ενός υψηλού παράγοντα Q περίπου 1 × 10⁶ επιτρέπει τη δημιουργία μιας εξαιρετικά συνεκτικής οπτικής χτένας μέσω διαδοχικών διεργασιών four-wave mixing.
Το παραγόμενο οπτικό φάσμα έχει κεντρικό μήκος κύματος 1550 nm και παρουσιάζει 3-dB εύρος ζώνης >2 THz, με OSNR που φτάνει τα 50 dB. Ένας ενσωματωμένος βρόχος ανάδρασης με ενσωματωμένες φωτοδιόδους (PD στην εικόνα) και ηλεκτρονικά εξασφαλίζει τη μακροχρόνια σταθεροποίηση του συστήματος, με πειραματικά επιβεβαιωμένη σταθερή λειτουργία >2000 ωρών χωρίς διακοπή. Ένα εξωτερικό γραφικό interface επιτρέπει τον έλεγχο των εσωτερικών στοιχείων και παραμέτρων της χτένας συχνοτήτων.
Το SLC της Enlightra παρήγαγε συνολική οπτική ισχύ 1 mW για όλα τα παραγόμενα μήκη κύματος, ενώ ένας ενισχυτής οπτικών ινών με ντόπινγκ έρβιου (EDFA) τοποθετήθηκε στην έξοδο για ενίσχυση της οπτικής ισχύος.
Στάδιο αποπολυπλεξίας–πολυπλεξίας και εξισορρόπησης καναλιών
Το στάδιο παραγωγής CW ακολούθησε ένας κόμβος αποπολυπλεξίας–πολυπλεξίας που επέτρεψε τη ρύθμιση της ισχύος κάθε καναλιού ξεχωριστά. Έτσι εξασφαλίστηκαν 16 κανάλια ίσης ισχύος με απόσταση καναλιών 0.8 nm, εντός του φασματικού παραθύρου 1535.9–1547.8 nm, με σφάλμα απόστασης ±0.01 nm. Η πολωτική κατάσταση κάθε καναλιού ρυθμίστηκε επίσης μεμονωμένα, ώστε να εξασφαλιστεί αποδοτική διαμόρφωση πλάτους και των 16 μηκών κύματος στο επόμενο στάδιο διαμόρφωσης.
Ένας δεύτερος EDFA τοποθετήθηκε μετά τον πολυπλέκτη για αντιστάθμιση απωλειών, ενώ ένα φίλτρο διέλευσης ζώνης (BPF) 12 nm απομάκρυνε τον θόρυβο ASE. Το φιλτραρισμένο πολυ-λ σήμα, με συνολική μέση ισχύ 28.1 mW (~1.8 mW ανά κανάλι), κατευθύνθηκε σε έναν Mach–Zehnder διαμορφωτή (MZM) από επαμφοτερίζον φώσφορο (InP) με ηλεκτρο-οπτικό εύρος ζώνης 35 GHz (Fraunhofer HHI InP MZM 64 Gbaud). Ο MZM οδηγούνταν από έναν arbitrary waveform generator (AWG – Keysight M8194A) για την παραγωγή του διανύσματος γραμμής βαρών
Wᵢ.
Το AWG παρήγαγε ηλεκτρικό σήμα ισχύος 350 mV, το οποίο ενισχυόταν από RF amplifier (SHF M804B) ώστε να φτάνει περίπου τα 3.5 V, όπως απαιτεί ο InP MZM. Με αυτόν τον τρόπο, το διανύσμα βαρών Wᵢ αποτυπωνόταν ως χρονική ακολουθία και στα 16 μήκη κύματος.
Μετά από οπτική ενίσχυση στην έξοδο του W-modulator, το σήμα χωρίστηκε σε 16 χωρικά αντίγραφα μέσω splitter 1:16, ενώ τα 16 WDM σήματα αποσυσχετίστηκαν με διαφορετικά μήκη οπτικών ινών πριν εισέλθουν στις αντίστοιχες εισόδους του AWGR.
Το AWGR και η κυκλική δρομολόγηση μήκους κύματος
Ο AWGR που χρησιμοποιήθηκε (Semicon SAWG-G-100G-32-32-C) διαθέτει 32 εισόδους και 32 εξόδους με εύρος ζώνης 3 dB ίσο με 0.4 nm. Στο πείραμα αξιοποιήσαμε μόνο τις 16 εισόδους και 16 εξόδους, λειτουργώντας ουσιαστικά ως AWGR 16 × 16.
Κατά συνέπεια, το διανύσμα βαρών Wᵢ που εισέρχεται από μια συγκεκριμένη είσοδο εμφανίζεται σε όλες τις 16 εξόδους, αλλά σε διαφορετικό μήκος κύματος λόγω της κυκλικής δρομολόγησης. Έτσι, κάθε έξοδος του AWGR μεταφέρει 16 διαφορετικά μήκη κύματος, το καθένα προερχόμενο από διαφορετική είσοδο και φέρον ένα χρονικά μετατοπισμένο αντίγραφο του Wᵢ.
Για τον υπολογισμό του στοχευμένου Wᵢ, επιλέγεται μόνο το κατάλληλο μήκος κύματος από τα 16 που εξέρχονται από την ίδια έξοδο.
Στάδιο διαμόρφωσης των διανυσμάτων εισόδου
Το πολυ-λ σήμα στην k-οστή έξοδο του AWGR χωρίστηκε μέσω splitter 1:16, παράγοντας 16 αντίγραφα. Κάθε έξοδος τροφοδοτήθηκε σε έναν LiNbO₃ MZM (iXBlue MX-LN-40) με εύρος ζώνης 40 GHz, ο οποίος διαμόρφωνε το αντίστοιχο διανύσμα εισόδου xˡ.
Ο LiNbO₃ MZM οδηγούνταν από το AWG ώστε να παράγει τη χρονική ακολουθία xˡ, με RF amplifier (SHF L806A) να ενισχύει το σήμα των 200 mV.
Με τη διαδοχική σύνδεση του MZM εισόδου στις 16 εξόδους του splitter που αντιστοιχεί στην έξοδο k του AWGR, αποκτήσαμε το προϊόν MbMM. Επαναλαμβάνοντας τη διαδικασία για όλες τις εξόδους του AWGR, υπολογίστηκαν όλα τα απαιτούμενα MbTM προϊόντα.
Ανάλυση Hadamard και καταγραφή σήματος
Για την ανάλυση των διαφορετικών Hadamard products που μεταφέρονταν από κάθε μήκος κύματος, το πολυ-λ σήμα αποπολυπλεξίστηκε σε 16 επιμέρους μήκη κύματος. Κάθε κανάλι ενισχύθηκε σε EDFA και στη συνέχεια πέρασε από BPF 0.55 nm πριν εισέλθει σε φωτοδίοδο 70 GHz (Finisar XPDV3120), με καταγραφή σε real-time oscilloscope 256 GSa/s (Keysight UXR0704AP).
Στο RTO εφαρμόστηκε λογισμικό φίλτρο με ρυθμιζόμενο εύρος 3 dB (20 ή 32 GHz) για μείωση του θορύβου PD.
Η ολοκλήρωση (integration) και η μη-γραμμική ενεργοποίηση (activation function, AF) υλοποιήθηκαν εξω-γραμμικά μέσω λογισμικού.
FIG. 2.
IV. ΠΕΙΡΑΜΑΤΙΚΗ ΕΠΙΚΥΡΩΣΗ ΣΕ ΕΦΑΡΜΟΓΕΣ ΒΑΘΙΑΣ ΜΑΘΗΣΗΣ
Η πειραματική επικύρωση της προτεινόμενης αρχιτεκτονικής MbTM πραγματοποιήθηκε σε δύο διαφορετικές εφαρμογές Τεχνητής Νοημοσύνης που αξιοποιούν δύο διαφορετικά μοντέλα Βαθιάς Μάθησης (DL) και αντίστοιχες διαμορφώσεις νευρωνικών δικτύων (NN). Ο σκοπός των δύο εφαρμογών ήταν:
(i) κυβερνοασφάλεια, μέσω ταυτοποίησης επιθέσεων DDoS σε Data Centers (DCs) μέσα από ανάλυση της τηλεμετρίας πακέτων και διάκριση κακόβουλων και μη κακόβουλων πακέτων, και
(ii) ταξινόμηση χειρόγραφων ψηφίων, χρησιμοποιώντας το σύνολο δεδομένων MNIST.
Η διαδικασία εκπαίδευσης για τις εργασίες DDoS και MNIST ξεκίνησε με την υλοποίηση των αντίστοιχων μοντέλων NN σε λογισμικό, δηλαδή ενός FC για την περίπτωση DDoS και ενός CNN για το MNIST, χρησιμοποιώντας το πλαίσιο PyTorch. Παράλληλα, ακολουθώντας τον αγωγό εργασίας που περιγράφεται στην Αναφ. 38, εξάγαμε το θόρυβο του υλικού (hardware), τον οποίο μοντελοποιήσαμε βάσει της τυπικής απόκλισης (std) για κάθε στοχευμένη ταχύτητα λειτουργίας. Όπως περιγράφεται και στο Συμπληρωματικό Υλικό, Τμήμα S1, αυτή η διαδικασία επέτρεψε την εξαγωγή της ισοδύναμης ανάλυσης σε bits ως προς τον θόρυβο (NEB) για το φωτονικό υλικό, η οποία στη συνέχεια καθόρισε τους περιορισμούς κατά την εκπαίδευση.
A. Εφαρμογή 1: Ταυτοποίηση επιθέσεων DDoS
Το πρώτο βήμα ήταν η εφαρμογή μιας γραμμικής μείωσης διαστασιμότητας στο σύνολο δεδομένων DDoS χρησιμοποιώντας PCA, ώστε να περιοριστεί το μέγεθος του διανύσματος εισόδου των δεδομένων τηλεμετρίας σε 6. Η διαδικασία εξαγωγής χαρακτηριστικών του συνόλου δεδομένων DDoS παρουσιάζεται αναλυτικά στην Αναφ. 42.
Μετά από κάθε στρώση, η ψηφιακή συνάρτηση ενεργοποίησης sigmoid παρείχε τη μη γραμμικότητα του συστήματος. Το NN εκπαιδεύτηκε με τον βελτιστοποιητή Adam⁴³ για 100 εποχές, εφαρμόζοντας σκληρούς περιορισμούς στα βάρη, επιβάλλοντας μη αρνητικές τιμές εντός του εύρους [0, 1].
Οι περιορισμοί στα βάρη ενσωματώθηκαν στην εκπαίδευση μέσω ενός όρου ποινής στη συνάρτηση κόστους, ο οποίος διαμορφώθηκε ως:
[
\mathcal{L} = L_c + \alpha \sum_k \frac{1}{N_k M_k} \sum_{i,j} \max(0, -w_{k,i,j})
\tag{1}
]
όπου (L_c) είναι η cross-entropy loss και (\alpha) ο συντελεστής βαρύτητας του όρου ποινής (default: (\alpha = 10)). Τα (N_k) και (M_k) ορίζουν τα fan-in και fan-out της k-οστής στρώσης. Επιπλέον, οι σκληροί περιορισμοί για το clipping των βαρών στο εύρος [0, 1] εφαρμόστηκαν μετά τη δέκατη εποχή, μετά το optimization step.
B. Εφαρμογή 2: CNN για ταξινόμηση MNIST
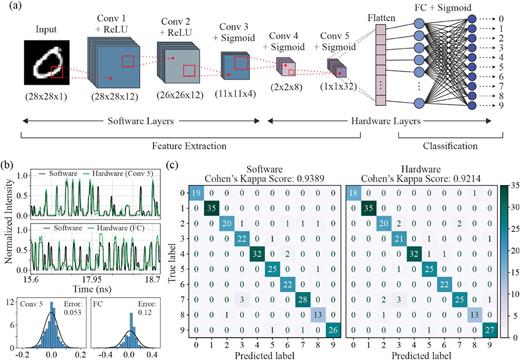
Η υλοποίηση του CNN για την ταξινόμηση MNIST χρησιμοποίησε τρεις λογισμικές συνελικτικές στρώσεις, δύο φωτονικές συνελικτικές στρώσεις, και μία φωτονική fully connected στρώση.
Η ραχοκοκαλιά χαρακτηριστικών (software backbone) αποτελούνταν από τρεις συνελικτικές στρώσεις:
- Conv 1, Conv 2: πυρήνας 3 × 3, τρία κανάλια έκαστη, με ψηφιακή ReLU ως μη γραμμικότητα.
- Conv 3: πυρήνας 3 × 3, τέσσερα κανάλια, stride = 2 και dilation = 2, με ψηφιακή sigmoid ως μη γραμμικότητα.
Η έξοδος του backbone (feature map 4 καναλιών, 11 × 11) τροφοδοτήθηκε σε στρώσεις που υλοποιήθηκαν μέσω του φωτονικού υλικού.
Οι φωτονικές συνελικτικές στρώσεις ήταν:
- Conv 4: πυρήνας 4 × 4, οκτώ κανάλια, stride = 4.
- Conv 5: πυρήνας 2 × 2, 32 κανάλια.
Η έξοδος της Conv 5 μετατράπηκε (flattened) σε διανύσμα 32 στοιχείων για την τελική οπτική στρώση ταξινόμησης (FC).
Η μη γραμμικότητα των φωτονικών στρώσεων εξήχθη πειραματικά μέσω ενός προγραμματιζόμενου οπτο-ηλεκτρο-οπτικού συστήματος, όπως παρουσιάζεται στην Αναφ. 44.
Το CNN εκπαιδεύτηκε end-to-end για 75 εποχές, με διαφορετική στρατηγική βελτιστοποίησης για το software backbone και τις οπτικές στρώσεις:
Software backbone
- Βελτιστοποιητής Adam
- Learning rate = 0.001
- Learning rate scheduler που μειώνει το LR κατά 50% κάθε 25 εποχές
Φωτονικές στρώσεις
- Περιορισμός σε 3-bit precision
- Χρήση normalized quantization-aware training³⁹
- Βελτιστοποίηση με multiplicative Adam⁴⁰ ώστε η μη αρνητικότητα των βαρών να διατηρείται
- Εφαρμογή μόνο του upper-bound penalty term της εξ. (1) με (\alpha = 1)
Με αυτόν τον τρόπο, οι σκληροί περιορισμοί των φωτονικών βαρών αμβλύνθηκαν, επιτρέποντας εκπαίδευση συμβατή με τις φυσικές ιδιότητες του φωτονικού υλικού.
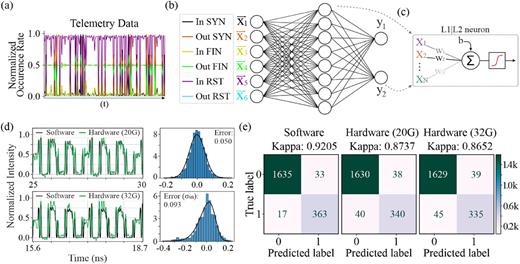
Η Εικ. 3(a) απεικονίζει ένα παράδειγμα δεδομένων τηλεμετρίας της κυκλοφορίας δεδομένων εντός ενός Data Center (DC), τα οποία χρησιμοποιήθηκαν για την εργασία αναγνώρισης επιθέσεων DDoS. Τα δεδομένα τηλεμετρίας κατηγοριοποιήθηκαν σε έξι κλάσεις, που αντιστοιχούν στα έξι διανύσματα εισόδου της πρώτης πλήρως συνδεδεμένης (FC) στρώσης του νευρωνικού δικτύου, όπως φαίνεται στην Εικ. 3(b), ακολουθούμενα από μια έξοδο FC στρώσης με δύο εξόδους. Κάθε νευρώνας της στρώσης 1 (L1) και της στρώσης 2 (L2) περιγράφεται από τη διάταξη της Εικ. 3(c).
Πριν από την αξιολόγηση, εφαρμόστηκε μια προκαταρκτική διαδικασία pre-emphasis (συζητείται στο Συμπληρωματικό Υλικό) για να αντισταθμιστούν:
(i) ο θόρυβος που προέρχεται από την περιορισμένη συχνοτική απόκριση των χρησιμοποιηθέντων διαμορφωτών και
(ii) οι μη γραμμικότητες εντός του ηλεκτρο-οπτικού συστήματος.
Για να επιτραπεί στην αρχιτεκτονική του επεξεργαστή να αξιοποιήσει όλους τους διαμορφωτές βαρών και εισόδων για χρήσιμους υπολογισμούς χωρίς να θυσιάζει κανένα μήκος κύματος ή διαμορφωτή για την αναπαράσταση αρνητικών αριθμών,⁴⁵ το NN ταξινόμησης DDoS εκπαιδεύτηκε ώστε να επιτρέπει μόνο μη αρνητικές τιμές, με χρήση optics-informed DL models.⁴
Η Εικ. 3(d) παρουσιάζει τα δεδομένα που προέκυψαν από το λογισμικό μαζί με τα πειραματικά ίχνη χρόνου των Hadamard products
[
\mathbf{x} \circ \mathbf{W}
]
που αποκτήθηκαν στην πρώτη έξοδο του splitter συνδεδεμένη με την πρώτη έξοδο του AWGR στο μήκος κύματος λ₁ και για δύο διαφορετικούς ρυθμούς συμβόλων, δηλαδή 20 και 32 Gbaud. Παρατηρείται ότι τα πειραματικά ίχνη ακολουθούν πολύ κοντά τα αντίστοιχα αποτελέσματα λογισμικού.
Η κατανομή θορύβου τόσο στα 20 όσο και στα 32 Gbaud παρουσιάζεται επίσης στην Εικ. 3(d). Για τη λειτουργία στα 20 Gbaud, η κατανομή προσεγγίζεται με Gaussian fit με τυπική απόκλιση STD = 0.05. Για την περίπτωση των 32 Gbaud, λόγω της παρουσίας αρνητικής ουράς στο ιστόγραμμα, χρησιμοποιήθηκε η κατανομή Azzalini skew-normal,⁴⁶ με προκύπτουσα σSN = 0.093.
Παρόμοια αποτελέσματα λήφθηκαν για όλα τα μήκη κύματος σε όλες τις 16 εξόδους του σταδίου split-and-modulate σε κάθε θύρα εξόδου του AWGR.
Για την αναγνώριση επιθέσεων DDoS χρησιμοποιήθηκε σύνολο 2048 δειγμάτων, από τα οποία το 81.45% (1668) ήταν benign και το 18.55% (380) malicious, οδηγώντας σε έντονα μη ισορροπημένο dataset. Ο δείκτης Cohen’s kappa-score²⁷,⁴⁷ λαμβάνει υπόψη την ανισορροπία των κλάσεων και γι’ αυτό παρέχει πιο ακριβή αποτίμηση στην τελική επικύρωση.
Οι πίνακες σύγχυσης που προέκυψαν από:
• το inference σε λογισμικό,
• την υλοποίηση του hardware στα 20 Gbaud, και
• την υλοποίηση του hardware στα 32 Gbaud
παρουσιάζονται στην Εικ. 3(e), μαζί με τις αντίστοιχες τιμές kappa.
Τα αποτελέσματα για το υλικό —0.8718 στα 20 Gbaud και 0.8677 στα 32 Gbaud— δείχνουν εξαιρετική απόδοση, με ελάχιστη υποβάθμιση σε σχέση με την εκτέλεση λογισμικού.
FIG. 3.
Για την αξιολόγηση της επίδοσης του φωτονικού επιταχυντή τεχνητής νοημοσύνης και σε συνελικτικά νευρωνικά δίκτυα (CNNs), πραγματοποιήθηκε μια δεύτερη διαδικασία πειραματικής επικύρωσης για την ταξινόμηση χειρόγραφων ψηφίων μέσω ενός υβριδικού NN λογισμικού/υλικού. Πιο συγκεκριμένα, η τοπολογία του NN αποτελούνταν από πέντε συνελικτικές στρώσεις και μία πλήρως συνδεδεμένη στρώση για την τελική ταξινόμηση. Από αυτές τις στρώσεις, οι τρεις πρώτες συνελικτικές στρώσεις εκτελέστηκαν σε λογισμικό και ήταν υπεύθυνες για την αρχική μείωση διαστασιμότητας, ενώ οι δύο επόμενες συνελικτικές στρώσεις και η τελική πλήρως συνδεδεμένη στρώση υλοποιήθηκαν στο φωτονικό υλικό.
Η τοπολογία του NN και το αντίστοιχο μέγεθος κάθε στρώσης απεικονίζονται στην Εικ. 4(a). Όπως και πριν, εφαρμόστηκε ένα optics-informed σχήμα εκπαίδευσης DL, ώστε να επιτρέπονται αυστηρά μη αρνητικές τιμές και να λαμβάνονται υπόψη οι περιορισμοί του φωτονικού υλικού ως προς το εύρος τιμών, την κβαντοποίηση και τον θόρυβο.
Η Εικ. 4(b) παρουσιάζει μια ενδεικτική χρονοσειρά στην έξοδο της πέμπτης συνελικτικής στρώσης του CNN (Conv 5) και της στρώσης FC για τις πράξεις πολλαπλασιασμού λογισμικού και υλικού, μετά την ψηφιακή συσχέτιση, για χρονικό παράθυρο 4.7 ns ή 150 σύμβολα στα 32 Gbaud. Τα πειραματικά ίχνη ακολουθούν πολύ στενά τα αντίστοιχα ίχνη λογισμικού, με παρόμοια αποτελέσματα να σημειώνονται για όλα τα μήκη κύματος σε όλες τις εξόδους του PNN.
Η κατανομή του θορύβου όλων των κυματομορφών εξόδου φαίνεται στην ίδια εικόνα και αποκαλύπτει τιμή τυπικής απόκλισης (STD) μόλις 0.053 για τη στρώση Conv 5 και 0.12 για τη στρώση FC.
Η συγκεκριμένη εργασία NN ταξινόμησε συνολικά 256 εικόνες μέσω inference σε λογισμικό και υλικό, με σχετικά ισορροπημένα υποσύνολα ανά κλάση. Οι πίνακες σύγχυσης των ταξινομήσεων λογισμικού και υλικού απεικονίζονται στην Εικ. 4(c).
Το inference λογισμικού για τα 256 δείγματα έφθασε 94.53% ακρίβεια, ενώ το inference υλικού, σε λειτουργία στα 32 Gbaud, πέτυχε 92.57% ακρίβεια. Η διαφορά αυτή αντιστοιχεί σε εσφαλμένη ταξινόμηση μόλις πέντε δειγμάτων στο υλικό.
Οι τιμές kappa-score υπολογίστηκαν επίσης, ώστε να ληφθεί υπόψη η ελαφρώς ανισόρροπη κατανομή των κλάσεων στο dataset, αποκαλύπτοντας τιμές 0.9389 για το λογισμικό και 0.9214 για το υλικό.
FIG. 4.
V. ΣΥΖΗΤΗΣΗ
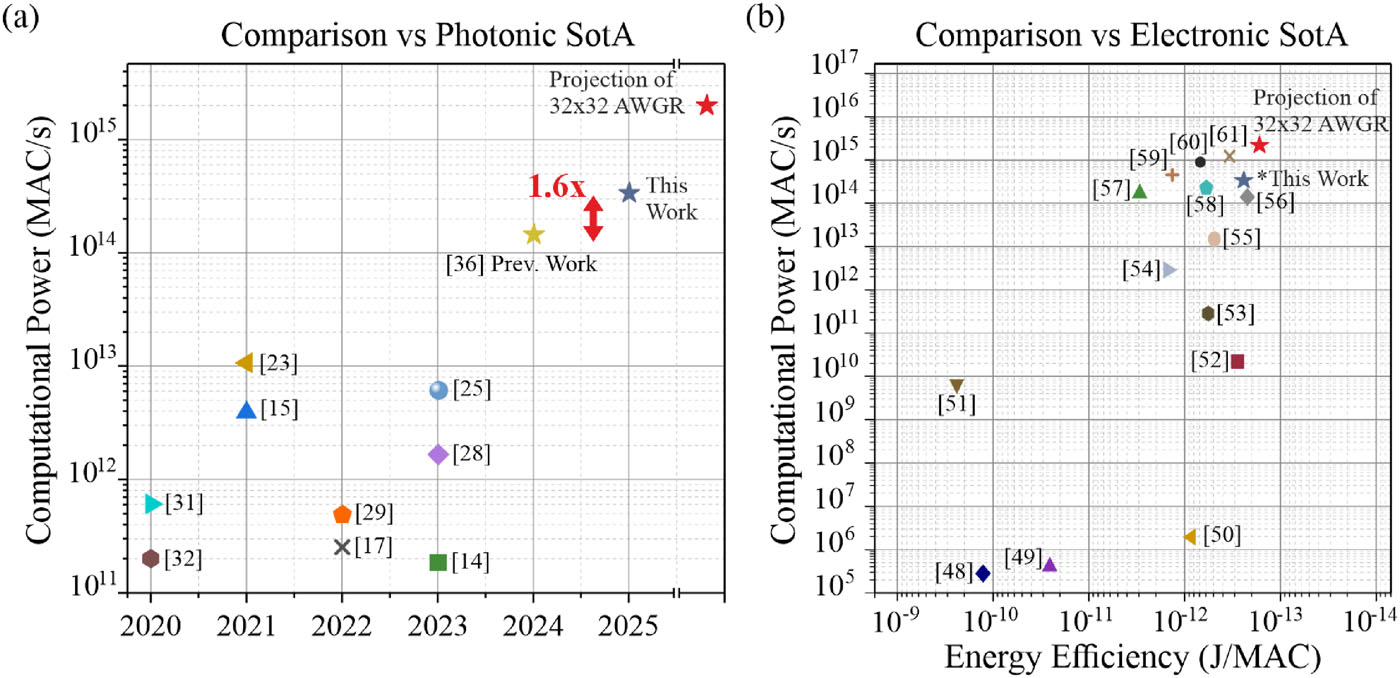
Ο προτεινόμενος πολυδιάστατος επιδείκτης (demonstrator) πολλαπλασιασμού τανυστών, βασισμένος σε AWGR, αποτελείτο από ένα AWGR 16 × 16, μια πηγή λέιζερ τύπου frequency comb που παρείχε τα 16 μήκη κύματος–φορείς, καθώς και υψηλής ταχύτητας MZMs. Με την οδήγηση των διαμορφωτών βαρών και σήματος εισόδου στα 20 Gbaud, η συνολική υπολογιστική ισχύς φτάνει τα 163.84 TOPS, τιμή που αυξάνεται στο 262 TOPS όταν ο ρυθμός συμβόλων αυξηθεί στα 32 Gbaud — επίδοση-ρεκόρ. Αυτό αντιστοιχεί σε ~60% αύξηση της υπολογιστικής ισχύος σε σύγκριση με την προηγούμενη εργασία μας³⁶ ή σε ~2200% αύξηση σε σύγκριση με την επόμενη υψηλότερη δημοσιευμένη επίδοση σε TOPS, δηλαδή την αρχιτεκτονική PNN της Αναφ. 23.
Η Εικ. 5(a) παραθέτει συγκριτικά τους πρόσφατους επιδείκτες PNN ως προς την επιτευχθείσα υπολογιστική επίδοση σε TOPS, όπου περιλαμβάνεται και μια πρόβλεψη για μελλοντική υλοποίηση ενός επιταχυντή AWGR 32 × 32. Με βάση την ίδια λογική, η Εικ. 5(b) απεικονίζει τη σύγκριση των οραματισμένων SiPho-integrated επιδεικτών μας με τους καθιερωμένους ηλεκτρονικούς επιταχυντές αιχμής.⁴⁸–⁶¹
Πρέπει να σημειωθεί ότι η ενεργειακή απόδοση της αρχιτεκτονικής μας προκύπτει από τους υπολογισμούς που παρουσιάζονται στο Συμπληρωματικό Υλικό, Τμήμα S3.
FIG. 5.
Η εκδοχή του υπερδιαστασιακού πρωτοτύπου υλικού βασισμένου σε AWGR που παρουσιάστηκε στο πλαίσιο της μελέτης υλοποιήθηκε με εξαρτήματα οπτικών ινών, ωστόσο μπορεί δυνητικά να μεταφερθεί σε μια ολοκληρωμένη εκδοχή σε κλίμακα chip, λαμβάνοντας υπόψη τις τρέχουσες δυνατότητες της τεχνολογίας ολοκλήρωσης φωτονικής πυριτίου (SiPho). Ένας βιώσιμος οδικός χάρτης για τη μεταφορά της αρχιτεκτονικής του πρωτοτύπου σε ολοκληρωμένη μορφή διαμορφώνεται αξιοποιώντας τις εξελίξεις στις οπτικές διασυνδέσεις, με στόχο την αξιοποίηση των πλεονεκτημάτων χαμηλού κόστους και μαζικής παραγωγής που προσφέρει η τεχνολογία SiPho.
Στην τρέχουσα υλοποίηση, οι συστοιχίες πομπού (T×) και δέκτη (Rx) βασίζονται σε ογκώδη εξαρτήματα οπτικών ινών· συνεπώς, το πρώτο βήμα αφορά τη μετάβαση σε διαθέσιμες διατάξεις T×, R× και T×/R× ολοκληρωμένες σε SiPho. Το επόμενο βήμα στοχεύει στην αντικατάσταση των υφιστάμενων συσκευών πυριτικών (de)MUX και AWGR με ολοκληρωμένα πρωτότυπα SiPho, ικανά να μειώσουν τις απαιτήσεις σε επιφάνεια ολοκληρωμένου κυκλώματος. Δείγματα υψηλού αριθμού θυρών έχουν ήδη αποδείξει τις δυνατότητές τους σε πλατφόρμες πυριτίου και νιτριδίου του πυριτίου, παρουσιάζοντας υπερ-συμπαγείς διατάξεις 32× (de)MUX και υψηλής απόδοσης πρωτότυπα AWGR 16 × 16, επιτρέποντας χαμηλές απώλειες και χαμηλές διακυμάνσεις κατασκευής, με στόχο AWGR με χαμηλό θόρυβο φάσης και μειωμένο διακαναλικό θόρυβο.
Το τελικό στάδιο της ολοκλήρωσης προβλέπει μια αρχιτεκτονική πολλαπλών chiplet, διασυνδεδεμένων μέσω ηλεκτρο-οπτικής πλακέτας PCB, ικανής να φιλοξενήσει τόσο ηλεκτρονικά όσο και φωτονικά υποσυστήματα. Η μετάβαση σε ολοκλήρωση τύπου chiplet προσφέρει κρίσιμο πλεονέκτημα, καθώς εξαλείφει τους περιορισμούς επιφάνειας και θερμικής διαχείρισης που είναι εγγενείς στους μονολιθικούς επεξεργαστές. Σε αυτό το σχήμα, οι διακριτές λειτουργίες διαχωρίζονται, καθεμία εκ των οποίων αναλαμβάνεται από διαφορετικό chiplet:
(i) ένα chiplet λέιζερ παράγει τους πολυκαναλικούς οπτικούς φορείς,
(ii) ένα chiplet διαμορφωτών υλοποιεί τις μονάδες κωδικοποίησης εισόδου και βαρών, σχηματίζοντας τον υπολογιστικό πυρήνα,
(iii) το AWGR ενσωματώνεται σε άλλο chiplet μαζί με τα (de)MUX και τις συστοιχίες φωτοδιόδων, και
(iv) ένα τελικό ηλεκτρονικό chiplet φιλοξενεί τα DAC/ADC και τα κυκλώματα οδήγησης.
Αυτή η αρθρωτή οργάνωση εξυπηρετεί δύο βασικούς σκοπούς:
- επιτρέπει την κλιμάκωση σε μεγαλύτερα συστήματα με τον συνδυασμό πολλαπλών μικρότερων chiplet T×/R×,
- επιτρέπει διαλειτουργικότητα μεταξύ διαφορετικών πλατφορμών φωτονικής πυριτίου σε ένα ενιαίο σύστημα.
Συνολικά, αυτός ο οδικός χάρτης βασίζεται σε εδραιωμένες τεχνολογίες οπτικών διασυνδέσεων και στις τρέχουσες τάσεις φωτονικής ολοκλήρωσης, προβλέποντας ότι το κόστος υλικού θα συνεχίσει να ακολουθεί την καθοδική πορεία που χαρακτηρίζει τις φωτονικές διασυνδέσεις. Αν και το παρόν σχήμα θα μπορούσε να αποτελέσει πιθανή κατεύθυνση για την υλοποίηση επιταχυντών τανυστών μεγάλης κλίμακας βασισμένων σε AWGR, η παρούσα συζήτηση λειτουργεί ως προκαταρκτική προοπτική, καθώς μια λεπτομερής διερεύνηση τέτοιων υλοποιήσεων πολλαπλών chiplet υπερβαίνει το εύρος της μελέτης. Παρά ταύτα, έχουμε ήδη ξεκινήσει προσπάθειες προς αυτή την κατεύθυνση, οι οποίες θα μπορούσαν να επιτρέψουν πλήρους κλίμακας υλοποιήσεις της προτεινόμενης αρχιτεκτονικής.
Παρά την ύπαρξη οδικού χάρτη για ενσωμάτωση, η κλιμάκωση των λόγων διακλάδωσης 1:N και 1:S παραμένει περιορισμένη.
Για την εκτίμηση των μέγιστων N και S, πρέπει πρώτα να οριστούν οι απαιτήσεις ισχύος λέιζερ και ενίσχυσης, που θα καθορίσουν:
(i) τον αριθμό των ενεργών στοιχείων και
(ii) την αντίστοιχη κατανάλωση ισχύος.
Οι τιμές αυτές μπορούν να υπολογιστούν με βάση το IL_Total. Αφετηρία είναι η ευαισθησία του κυκλώματος δέκτη (R_sens), που για την προβλεπόμενη τοπολογία SiPho AWGR τίθεται στα –16 dBm στα 20 Gbaud, σύμφωνα με την τρέχουσα απόδοση TIA.
Οι τιμές IL από τη βιβλιογραφία:
- IL_WDM = 1,6 dB,
- IL_mod = 3,7 dB,
- IL_AWGR = 3 dB.
Για κάθε τοπολογία AWGR N×N (N = 4, 8, 16, 32), η απώλεια διακλάδωσης υπολογίζεται ILS = 3 × log₂(N). Επομένως, όσο αυξάνεται η κλίμακα της τοπολογίας, τόσο αυξάνεται η απώλεια λόγω διακλάδωσης, απαιτώντας επιπλέον ενίσχυση. Πρέπει να ληφθεί υπόψη και το όριο ισχύος στον κυματοδηγό πριν την εμφάνιση μη γραμμικών φαινομένων (~16 dBm). Με βάση αυτούς τους περιορισμούς, πραγματοποιήθηκε ανάλυση για τον προσδιορισμό των εφικτών N και S. Η ισχύς ανά γραμμή comb υποτέθηκε σύμφωνα με την επόμενη γενιά των Si₃N₄ combs, με δυνατότητα επιλογής 16 ή 32 γραμμών, παρέχοντας ~10 mW ανά γραμμή και διακύμανση ±2 dB.
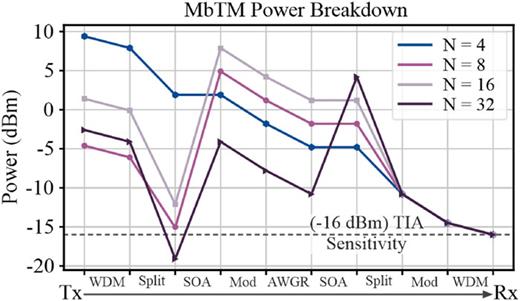
Το Σχήμα 6 παρουσιάζει την ανάλυση σκοπιμότητας ολοκλήρωσης του προτεινόμενου επιταχυντή MbTM, υποδεικνύοντας την ανάγκη για οπτική ενίσχυση σε N = 8, 16, 32:
- για N = 8 και N = 16 απαιτείται ένας ενισχυτής 20 dB,
- για N = 32 απαιτούνται δύο στάδια ενίσχυσης των 15 dB λόγω αυξημένων απωλειών.
Η ανάλυση αυτή παρέχει την πρώτη ένδειξη σκοπιμότητας για τον υπερδιαστασιακό επιταχυντή και αντανακλά τα μέγιστα N και S που επιτρέπει η γραμμικότητα ισχύος εντός των κυματοδηγών πυριτίου.
FIG. 6
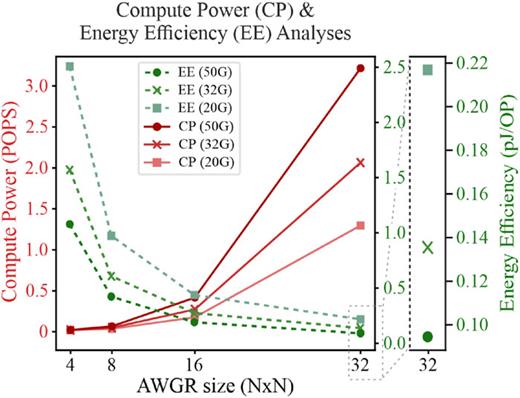
Το Σχήμα 7 παρουσιάζει τις προοπτικές κλιμάκωσης της αρχιτεκτονικής και απεικονίζει δύο βασικούς δείκτες των υπολογιστικών μηχανών, δηλαδή την υπολογιστική ισχύ (CP) και την ενεργειακή απόδοση (EE), σε σχέση με το μέγεθος του AWGR, λαμβάνοντας υπόψη ολοκληρωμένα φωτονικά στοιχεία τεχνολογίας αιχμής (συμπληρωματικό υλικό, S3).
Η ανάλυση προϋποθέτει τη χρήση ενός ολοκληρωμένου AWGR N × N, ενώ το PNN λειτουργεί σε τρεις διαφορετικούς ρυθμούς δεδομένων: 20 και 32 Gbaud, όπως παρουσιάστηκαν σε αυτή τη μελέτη, και έναν μελλοντικό στόχο των 50 Gbaud, ο οποίος έχει ήδη αποδειχθεί ότι μπορεί να υποστηρίξει εφαρμογές AI σε κλίμακα chip.
Για την εφικτότητα ολοκλήρωσης ολόκληρου του συστήματος, πρέπει επίσης να ληφθεί υπόψη ο συνολικός εντός-ζώνης διακαναλικός θόρυβος των συσκευών AWGR και (απο)πολυπλεξίας. Ο διακαναλικός θόρυβος μπορεί να μοντελοποιηθεί ως προσθετικός θόρυβος και να οριστεί ως άνω όριο σε σχέση με την αποτελεσματική bit-precision του συστήματος. Μια λεπτομερής ανάλυση των απαιτήσεων σε crosstalk μαζί με κλειστού τύπου όρια κλιμάκωσης παρέχεται στο συμπληρωματικό υλικό, Ενότητα S5.
Η ποσοτικοποίηση της EE απαιτεί λεπτομερή καταγραφή της κατανάλωσης ισχύος (PC) όλων των ενεργών στοιχείων, συμπεριλαμβανομένων των κυκλωμάτων DAC, του ολοκληρωτή, και των ADC. Οι υποθέσεις για την ταχύτητα και την ενεργειακή κατανάλωση μιας εκδοχής PNN σε κλίμακα chip παρατίθενται λεπτομερώς στο συμπληρωματικό υλικό.
Η απόδοση MbTM κλιμακώνεται με O(N³), και ο αριθμός των εκτελούμενων πράξεων υπολογίζεται ως
2·N³·B GOPS,
για K=N, με πιο λεπτομερή ανάλυση στην Ενότητα S4.
Ως εκ τούτου, η συνολική υπολογιστική ισχύς αυξάνεται κυβικά με τις διαστάσεις του AWGR, ενώ η ενεργειακή απόδοση βελτιώνεται, καθώς η συνολική κατανάλωση κλιμακώνεται με τον αριθμό των ενεργών στοιχείων, δηλαδή με O(N²).
Η υπολογιστική ισχύς και η ενεργειακή απόδοση βελτιώνονται επίσης με την αύξηση του ρυθμού μετάδοσης δεδομένων. Μια εκδοχή του 16 × 16 AWGR σε φωτονική πυριτίου, λειτουργώντας στα 32 Gbaud, μπορεί να επιτύχει συνολική υπολογιστική ισχύ 262 TOPS με ενεργειακή απόδοση 273 fJ/OP.
Αντίστοιχα, ένα AWGR 32 × 32 σε πυρίτιο, λειτουργώντας στα 50 Gbaud, μπορεί κατ’ αρχήν να επιτύχει υπολογιστική ισχύ έως:
2 × 32³ × 50 × 10⁹ = 3.276 POPS,
με συνολική κατανάλωση 309,5 W, υποδηλώνοντας ενεργειακή απόδοση περίπου 94 fJ/OP.
Παρότι η εκτιμώμενη απόλυτη κατανάλωση (~310 W) είναι υψηλότερη από τους σημερινούς ηλεκτρονικούς επιταχυντές, η πραγματική αξία της προτεινόμενης αρχιτεκτονικής έγκειται στην αναλογία throughput-per-watt.
Ενώ η υπολογιστική ισχύς κλιμακώνεται με O(N³), η κατανάλωση ισχύος αυξάνεται μόνο με O(N²), οδηγώντας σε συνολική βελτίωση κατά ~2× στην ενέργεια ανά πράξη.
Αυτό φαίνεται ξεκάθαρα όταν διπλασιάζεται ο αριθμός θυρών εισόδου/εξόδου του AWGR:
- η υπολογιστική ισχύς αυξάνεται κατά 8×,
- ενώ η κατανάλωση ισχύος αυξάνεται μόνο κατά ~4×.
Αυτή η συμπεριφορά κλιμάκωσης αποτελεί το βασικό πλεονέκτημα του προτεινόμενου hyperdimensional tensor engine. Η περαιτέρω ωρίμανση της τεχνολογίας SiPho αναμένεται να βελτιώσει επιπλέον την απόδοση διαμορφωτών, τις απώλειες AWGR και τις δυνατότητες συνεπικάλυψης ηλεκτρονικών–φωτονικών, μειώνοντας ακόμη περισσότερο την απόλυτη κατανάλωση και κλείνοντας το χάσμα με την ηλεκτρονική τεχνολογία, ενώ διατηρείται το πλεονέκτημα κλιμάκωσης.
FIG. 7.
VI. ΣΥΜΠΕΡΑΣΜΑΤΑ
Πραγματοποιήσαμε πειραματική επικύρωση μιας αρχιτεκτονικής MbTM, η οποία περιλαμβάνει πηγή λέιζερ comb, έναν AWGR 16 × 16 και ευρυζωνικούς MZM που οδηγούνται έως και σε ρυθμούς 32 Gbaud, προσφέροντας υπολογιστική ισχύ ρεκόρ 262 TOPS. Εκπαιδεύτηκαν δύο διαφορετικά μοντέλα βαθιάς μάθησης (DL) για αντίστοιχες εφαρμογές και αξιοποιήθηκαν για την πειραματική επικύρωση της προτεινόμενης διάταξης MbTM στον χώρο της τεχνητής νοημοσύνης: ένα πλήρως συνδεδεμένο νευρωνικό δίκτυο (FC NN) για την αναγνώριση επιθέσεων DDoS και ένα βαθύ νευρωνικό δίκτυο αποτελούμενο από πολλαπλά συνελικτικά στρώματα και ένα τελικό FC στρώμα για την ταξινόμηση MNIST.
Επιτεύχθηκε επιτυχής ταξινόμηση μεταξύ κακόβουλης και μη κακόβουλης κίνησης στο έργο αναγνώρισης DDoS, με πειραματικό Cohen’s kappa-score 0.8677 σε 2048 δείγματα inference, παρουσιάζοντας μόλις 0.05 υποβάθμιση σε σχέση με το λογισμικό. Η ταξινόμηση ψηφίων του MNIST πέτυχε πειραματική ακρίβεια 92.14% σε inference υλικού για 256 δείγματα, τιμή που προσεγγίζει στενά την απόδοση του λογισμικού (93.89%).
Τέλος, συζητήσαμε τις προοπτικές ολοκλήρωσης της προτεινόμενης αρχιτεκτονικής και αναδείξαμε ότι αποτελεί έναν πολλά υποσχόμενο οδικό χάρτη για περαιτέρω βελτιώσεις στην υπολογιστική ισχύ και ενεργειακή απόδοση. Η προβλεπόμενη αρχιτεκτονική AWGR, με αναβάθμιση σε διασυνδεσιμότητα 32 × 32 και ρυθμό υπολογισμού 50 Gbaud, αναμένεται να επιτρέψει υπολογιστική ισχύ 3.276 POPS, με κατανάλωση κάτω των 100 fJ/OP, δηλαδή αύξηση περίπου 298× σε σχέση με τους πιο προηγμένους φωτονικούς επιταχυντές σήμερα.
ΣΥΜΠΛΗΡΩΜΑΤΙΚΟ ΥΛΙΚΟ
Το συμπληρωματικό υλικό παρέχει πρόσθετες λεπτομέρειες για τη διαδικασία προέμφασης για γραμμικοποίηση του φωτονικού συνδέσμου, την επικύρωση της πολυ-μηκοκυμάτων λειτουργίας, την ανάλυση κατανομής κατανάλωσης ισχύος, την ανάλυση υπολογιστικής απόδοσης (throughput), την ανοχή σε διακαναλικό θόρυβο (crosstalk) και μια επεξηγηματική συζήτηση σχετικά με τη συμβατότητα του επιταχυντή AWGR με αλγόριθμους GEMM για συγκριτική αξιολόγηση. Περιλαμβάνει επίσης τα αναφερόμενα σχήματα και πίνακες (συμπληρωματικό υλικό, Σχήματα 1–2 και Πίνακες 1–2) που στηρίζουν τα αποτελέσματα και την ανάλυση του κύριου άρθρου.
ΕΥΧΑΡΙΣΤΙΕΣ
Η Enlightra ευχαριστεί τη Charlotte Bost για τη μελέτη της κατά τη γραμμική χαρακτηριστικοποίηση PIC και τον Lou Kanger για τη χαρακτηριστικοποίηση μη γραμμικότητας. Ευχαριστεί επίσης τον Alexey Feofanov για τη συμβολή του στην ανάπτυξη του Enlightra SLC.
Η μελέτη χρηματοδοτήθηκε εν μέρει από το πρόγραμμα Chips Joint Undertaking HAETAE (Grant No. 101194393) και τα προγράμματα Horizon 2020 Gatepost (Grant No. 101120938) και ALLEGRO (Grant No. 101092766).
ΔΗΛΩΣΕΙΣ ΣΥΓΓΡΑΦΕΩΝ
Σύγκρουση Συμφερόντων
Οι συγγραφείς δεν έχουν να δηλώσουν συγκρούσεις συμφερόντων.
Συγγραφική Συνεισφορά
(Παραθέτω κατά λέξη την αναλυτική κατανομή συνεισφορών όπως στο πρωτότυπο, σε επαγγελματική ελληνική απόδοση.)
- Christos Pappas: Εννοιολογικός σχεδιασμός (υποστηρικτικός), Επιμέλεια δεδομένων (ίση), Τυπική ανάλυση (κύρια), Μεθοδολογία (ίση), Επικύρωση (ίση), Συγγραφή – αρχικό κείμενο (κύρια), Συγγραφή – ανασκόπηση & επιμέλεια (κύρια).
- Antonios Prapas: Επιμέλεια δεδομένων (ίση), Τυπική ανάλυση (υποστηρικτική), Λογισμικό (κύριο), Επικύρωση (υποστηρικτική).
- Theodoros Moschos: Εννοιολογικός σχεδιασμός (υποστηρικτικός), Επιμέλεια δεδομένων (ίση), Τυπική ανάλυση (υποστηρικτική), Μεθοδολογία (υποστηρικτική).
- Manos Kirtas: Συγγραφή – αρχικό κείμενο (υποστηρικτική).
- Odysseas Asimopoulos: Λογισμικό (υποστηρικτικό), Οπτικοποίηση (υποστηρικτική).
- Apostolos Tsakyridis: Εννοιολογικός σχεδιασμός (ίσος), Μεθοδολογία (ίση), Εποπτεία (ίση), Συγγραφή – αρχικό κείμενο (ίση), Συγγραφή – ανασκόπηση & επιμέλεια (ίση).
- Miltiadis Moralis-Pegios: Εννοιολογικός σχεδιασμός (ίσος), Μεθοδολογία (ίση), Εποπτεία (ίση), Συγγραφή – αρχικό κείμενο (ίση), Συγγραφή – ανασκόπηση & επιμέλεια (ίση).
- Chris Vagionas: Εννοιολογικός σχεδιασμός (υποστηρικτικός), Εποπτεία (υποστηρικτική), Συγγραφή – αρχικό κείμενο (υποστηρικτική), Συγγραφή – ανασκόπηση & επιμέλεια (υποστηρικτική).
- Nikolaos Passalis: Εποπτεία (υποστηρικτική), Συγγραφή – αρχικό κείμενο (υποστηρικτική).
- Cagri Ozdilek: Επιμέλεια δεδομένων (υποστηρικτική), Πόροι (υποστηρικτικοί), Συγγραφή – αρχικό κείμενο (υποστηρικτική).
- Timofey Shpakovsky: Πόροι (υποστηρικτικοί).
- Alain Yuji Takabayashi: Συγγραφή – αρχικό κείμενο (υποστηρικτική).
- John D. Jost: Πόροι (ίσοι).
- Maxim Karpov: Πόροι (ίσοι).
- Anastasios Tefas: Εννοιολογικός σχεδιασμός (υποστηρικτικός), Λογισμικό (υποστηρικτικό), Εποπτεία (υποστηρικτική), Συγγραφή – αρχικό κείμενο (υποστηρικτική).
- Nikos Pleros: Εννοιολογικός σχεδιασμός (κύριος), Εποπτεία (ίση), Συγγραφή – αρχικό κείμενο (ίση), Συγγραφή – ανασκόπηση & επιμέλεια (ίση).
ΔΙΑΘΕΣΙΜΟΤΗΤΑ ΔΕΔΟΜΕΝΩΝ
Τα δεδομένα που υποστηρίζουν τα ευρήματα της μελέτης είναι διαθέσιμα από τον αντίστοιχο συγγραφέα κατόπιν αιτήματος.

{kind=link}